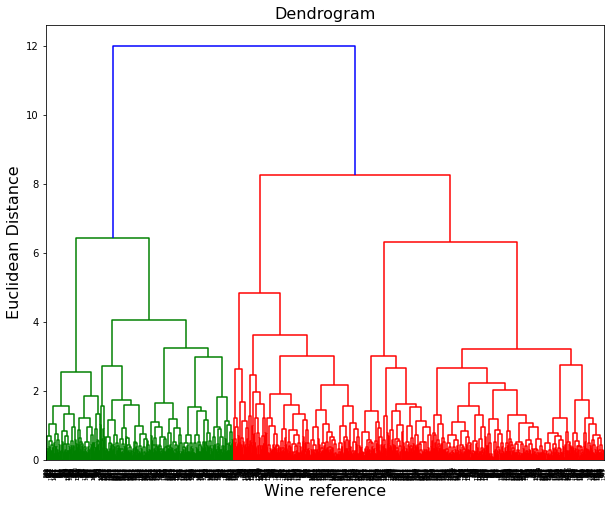
Wine dataset: Unsupervised learning for clustering wine references
It is well known that wine has motivated people to socialize, create, party, and adventure. It’s no wonder, billions of people around the globe identify as wine lovers!
In this dataset, we find 1600 wine references with the following features and the goal is to create clusters that group references by similarity. This way, we could classify a new wine reference, that has not been included in this analysis, in one of the clusters defined here. For this, we will use unsupervised learning with Hierarchical Clustering and KMeans technics.